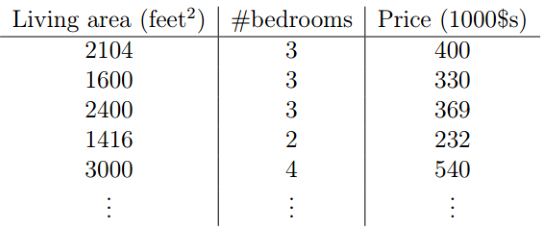
假设我们有下面这样的一组二维的住房数据,我们的目标是利用住房面积和卧室的数量来推测房屋的价格:
上述数据只有两个特征(面积和房屋数),我们可以给不同的特征赋予不同的权重 θ1, θ2,并加上一个偏移量 θ0 来构造一个线性模型来估计房屋的价格:
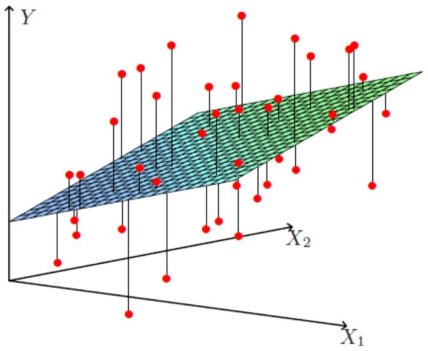
那么其表达式可以是这样的,其中θ都是未知的参数:
hθ(x)=θ0+θ1x1+θ2x2
当然,我们还可以用向量的形式来表示,令:
θ=⎝⎛θ0θ1θ2⎠⎞
x=⎝⎛1x1x2⎠⎞
则有:
hθ(x)=i=0∑nθixi=θTx
其中x是来自于样本的已知的值,θ是未知的值。上述式子可以用于有更多特征的情况,例如还可以加上房屋的地理位置,房屋的高度等特征。此线性模型对于其他的数据也是同样适用的。
既然是估计,那么肯定是存在误差的,对于第 i 个样本而言,其真实值与估计值的关系可以表示为:
y(i)=y^(i)+ε(i)=θTx(i)+ε(i)
我们认为 ϵ 是一个误差值,所有样本的误差在真实值上下波动,所以 ϵ 是独立同分布的,可以理解为总体样本的误差服从均值为0,方差为 σ^2 的正态分布:
ϵ(i)∼N(0,σ2)
令:
ε(i)=y(i)−y^(i)=y(i)−θTx(i)
则有:
y(i)−y^(i)∼N(0,σ2)
于是得到了真实值 y 的分布:
y(i)∼N(y^(i),σ2)
y 的概率密度函数为:
p(y(i)∣x(i);θ)=2πσ1exp(−2σ2(y(i)−y^(i))2)=2πσ1exp(−2σ2(y(i)−θTx(i))2)
由于样本的特征 x 以及它的真实值 y 均已知,上式可以看作是关于参数θ的函数,也就是似然函数。现在要做的就是求解参数θ的值,使得似然函数取值最大。令:
L(θ)=i=1∏mp(y(i)∣x(i);θ)=i=1∏m2πσ1exp(−2σ2(y(i)−θTx(i))2)
为了方便计算,对其取对数:
ℓ(θ)=logL(θ)=logi=1∏m2πσ1exp(−2σ2(y(i)−θTx(i))2)=i=1∑mlog2πσ1exp(−2σ2(y(i)−θTx(i))2)=mlog2πσ1−σ21⋅21i=1∑m(y(i)−θTx(i))2
因此,要让 L 最大,只需让下式最小即可:
J(θ)=21i=1∑m(hθ(x(i))−y(i))2
现在有了要优化的目标函数,可是θ的最优解是什么?要求解θ涉及矩阵的求导,可以参考机器学习中的矩阵基本求导公式。
∇θJ(θ)=∇θ(21(Xθ−y)T(Xθ−y))=∇θ(21(θTXT−yT)(Xθ−y))=∇θ(21(θTXTXθ−θTXTy−yTXθ+yTy))=21(2XTXθ−XTy−(yTX)T)=XTXθ−XTy
令上式子等于 0 求得驻点:
θ=(XTX)−1XTy
此时 θ 即为最优解。